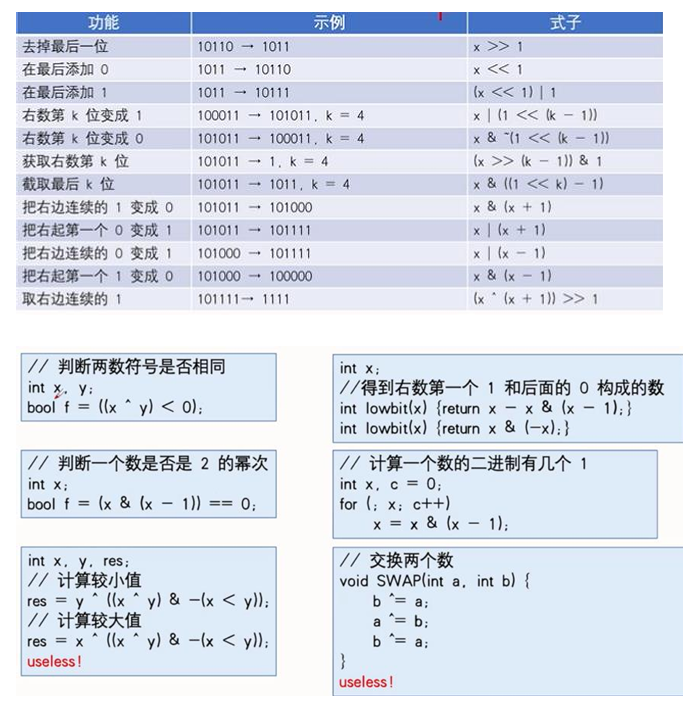
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
int a[N];
struct Node{
ll t,val,sz;
}seg[N*4];
void setting(int id,ll t) {
seg[id].val = seg[id].val + t*seg[id].sz;
seg[id].t = seg[id].t + t;
}
void pushdown(int id) {
if(seg[id].t != 0) {
setting(id *2,seg[id].t);
setting(id *2+1,seg[id].t);
seg[id].t = 0;
}
}
void update(int id) {
seg[id].sz = seg[id*2].sz+seg[id*2+1].sz;
seg[id].val = seg[id*2].val+seg[id*2+1].val;
}
void build(int id,int l,int r) {
if(l==r){
seg[id].val = a[l];
seg[id].sz = 1;
}else {
int mid = (l+r)/2;
build(id*2,l,mid);
build(id*2+1,mid+1,r);
update(id);
}
}
void modify(int id,int l,int r,int ql,int qr,ll t) {
if(l == ql && r == qr) {
setting(id,t);
return;
}
int mid = (l + r)/2;
pushdown(id);
if(qr<=mid) modify(id*2,l,mid,ql,qr,t);
else if (ql>mid) modify(id*2+1,mid+1,r,ql,qr,t);
else {
modify(id*2,l,mid,ql,mid,t);
modify(id*2+1,mid+1,r,mid+1,qr,t);
}
update(id);
}
ll query(int id,int l, int r,int ql,int qr) {
if(l == ql && r == qr) return seg[id].val;
int mid = (l + r)/2;
pushdown(id);
if(qr<=mid) return query(id*2,l,mid,ql,qr);
else if (ql>mid) return query(id*2+1,mid+1,r,ql,qr);
else {
return
query(id*2,l,mid,ql,mid)+query(id*2+1,mid+1,r,mid+1,qr);
}
}
|