MQ面试题
⚫ 熟悉Rocketmq的使用,掌握持久化机制,消息可靠性,延迟消费等,解决过消息积压,消息逆序等问题;
使用场景(系统解耦和流量削峰)
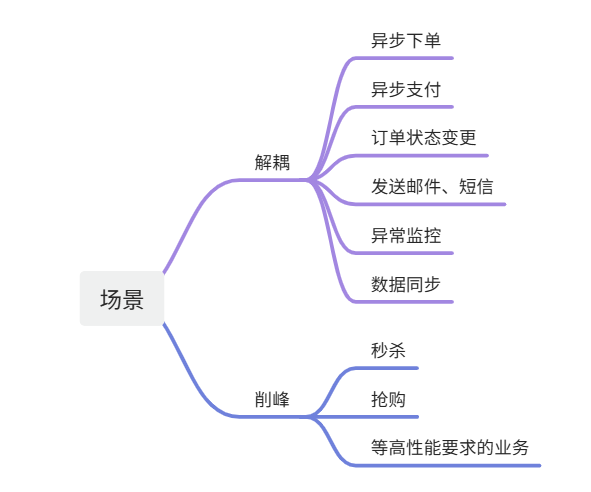
异步通信场景:
MQ可以实现消息的异步传递,避免了请求等待的时间,提高了系统的响应速度和吞吐量。
常见的应用场景有异步下单、异步支付等,例如在电商平台中,当用户下单或支付后,这些操作可以被转化为消息发送至MQ,由后台服务异步处理,而用户无需等待操作完成即可进行其他操作。
分布式系统场景:
MQ可以在分布式系统中实现各个节点之间的高效通信,解决网络延迟、网络抖动等问题。
常见的应用场景有分布式任务调度、分布式事务等。例如,在微服务架构中,服务之间的数据交互可以通过MQ实现,降低服务的耦合度,提高系统的可扩展性和可维护性。
解耦系统场景:
MQ可以将系统各个模块之间的耦合度降低,实现系统的解耦。
常见的应用场景有日志收集、异常监控等。通过使用MQ,可以将这些操作从主业务逻辑中分离出来,降低系统的复杂性。
流量削峰场景:
MQ可以在高并发场景下,实现流量的削峰,避免系统崩溃或响应变慢。
常见的应用场景有秒杀、活动抢购等。通过使用MQ缓存请求,后台服务可以按顺序处理,避免大量请求直接冲击系统。
消息通知场景:
MQ可以实现消息的实时通知,提高用户体验。
常见的应用场景有订单状态变更通知、短信验证码发送等。用户可以在无需主动查询的情况下,实时获取到最新的信息。
数据同步场景:
MQ可以实现不同系统之间数据的同步,保证数据的一致性。
常见的应用场景有缓存同步、库存同步等。当某个系统修改了共享数据后,可以通过MQ通知其他系统同步数据。
缺点
系统复杂性增加
引入消息队列会增加系统的复杂性,包括系统架构、开发和运维的复杂性。需要处理消息的生产、消费、路由、持久化、重试、重复消息处理等问题。
在一个简单的单体应用中,引入消息队列需要重新设计系统架构,并且需要开发和维护消息生产者和消费者代码,这增加了系统的复杂性。
消息丢失风险
尽管大多数消息队列系统提供了消息持久化和重试机制,但在极端情况下(如硬件故障、网络故障等),仍然存在消息丢失的风险。
在网络分区或硬盘故障的情况下,消息可能会丢失,导致系统无法处理某些关键操作,如订单处理中的支付请求。
消息重复
由于网络故障或消费者处理失败,消息队列系统可能会重发消息,这会导致消息重复。消费者需要具备幂等性,能够正确处理重复消息。
在支付系统中,如果支付请求被重复处理,可能会导致用户被多次扣款。因此,消费者需要确保每个支付请求只被处理一次。
延迟
消息队列引入了额外的网络传输和排队时间,这可能会导致消息处理的延迟。对于某些实时性要求高的系统,这可能是一个问题。
在实时交易系统中,消息处理的延迟可能会影响交易的及时性和准确性,进而影响用户体验和系统的可靠性。
运维成本
消息队列系统需要专门的运维和监控,确保其高可用性和性能。这包括集群管理、节点监控、日志分析、性能调优等。
Kafka、RabbitMQ 等消息队列系统需要专门的运维人员进行日常管理和维护,包括集群的扩展、故障处理、性能调优等。
一致性问题
在分布式系统中,使用消息队列可能会导致数据一致性问题。需要设计合理的事务管理和一致性保障机制。
在订单系统中,订单创建和库存扣减需要保证一致性。如果订单创建成功但库存扣减失败,可能会导致数据不一致,需要设计补偿机制来处理这种情况。
常见问题与解决方案
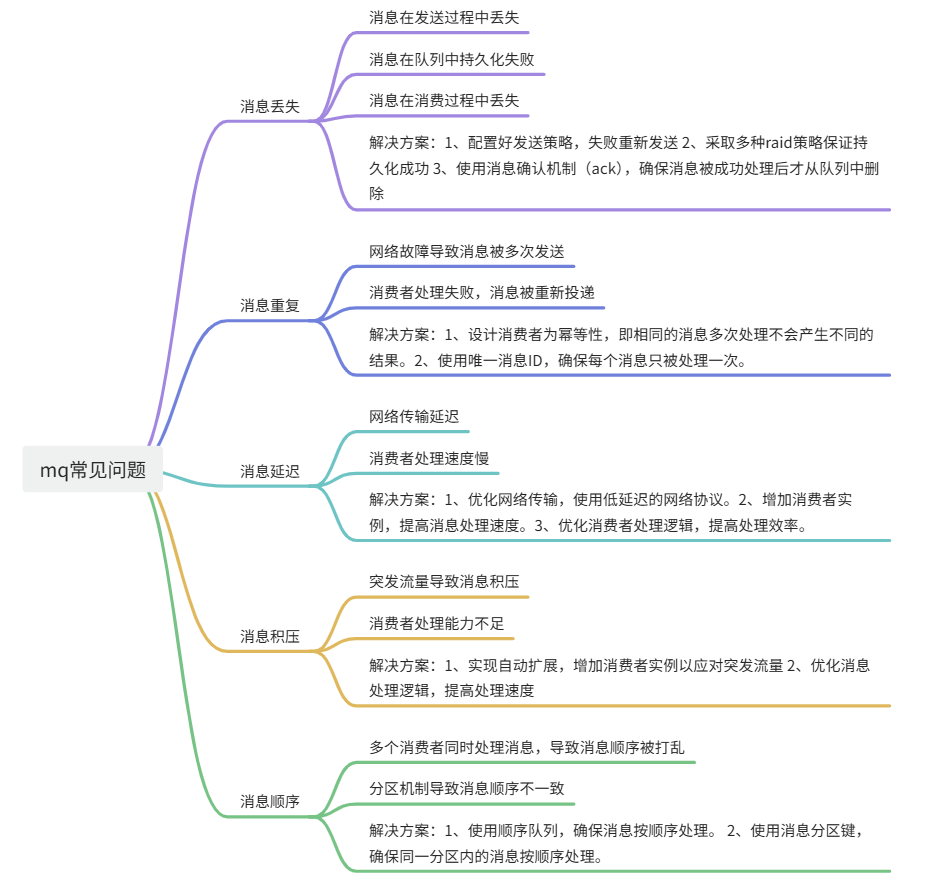
保障消息的顺序消费
消息顺序消费问题的原因
1、 多个消费者并行处理:当多个消费者并行处理消息时,消息的处理顺序可能会与发送顺序不一致。
2、 分区机制:在分布式消息队列系统中,消息通常会被分区存储和处理。不同分区内的消息顺序可能会被打乱。
3、 重试机制:消息处理失败时,重试机制可能会导致消息顺序被打乱。
解决消息顺序消费问题的方案
使用顺序队列:顺序队列确保消息按照发送的顺序进行处理。常见的消息队列系统,如Kafka、RabbitMQ等,都支持顺序队列。 在Kafka中,可以通过使用单个分区来保证消息的顺序性。因为同一个分区内的消息是按顺序存储和处理的。其他消息队列也有响应的机制。
使用消息分区键:通过设置消息分区键,确保同一分区内的消息按顺序处理。分区键通常是业务相关的标识符,如订单ID、用户ID等。 在Kafka中,可以使用分区键来确保同一订单的消息发送到同一分区。
单消费者模式:在某些情况下,可以使用单消费者模式,即一个队列只有一个消费者。这样可以确保消息按顺序处理。 在RabbitMQ中,可以配置队列为单消费者模式。
消息排序:在某些场景中,可以在消费端进行消息排序。消费者在处理消息前,对消息进行排序,确保处理顺序。这种场景其实实际很难使用,因为你不知道消息多少,比较适合固定时间内的批量处理,可以排序。
避免消息丢失
消息生产过程中的可靠性保证:
确保消息被成功发送到消息队列系统。比如 Kafka:使用acks配置,设置为all,确保消息被所有副本确认。RabbitMQ 则使用publisher confirms,确保消息被队列接收。
消息传输过程中的可靠性保证
在网络传输失败时进行重试。同时使用 TCP,确保消息传输的可靠性。
消息存储过程中的可靠性保证
确保消息在磁盘上持久化存储。Kafka默认情况下消息是持久化存储的。RabbitMQ 则需要设置队列和消息为持久化。 在RabbitMQ中设置持久化:
消息消费过程中的可靠性保证
消息确认机制(Consumer Acknowledgment):确保消息被成功处理后才从队列中删除。比如 Kafka使用手动提交偏移量。RabbitMQ 则使用手动确认机制(manual acknowledgment)。
其他注意事项
1、 监控和报警:实时监控消息队列系统的运行状态,设置报警机制,及时发现和处理消息丢失问题。
2、 日志记录:记录消息的生产、传输、存储和消费日志,便于问题排查和恢复。
3、 消息重试机制:配置合理的消息重试机制,确保在处理失败时进行重试。
4、 高可用部署:部署高可用集群,确保在节点故障时系统能够自动切换,避免消息丢失。
避免消息重复投递或重复消费
消息幂等性
消息幂等性是指无论消息被处理多少次,结果都是相同的。实现幂等性是避免重复消费的基础。
主要可以通过如下方式进行实现:
1、 唯一标识:每条消息都带有一个唯一标识(如 UUID),在处理消息时,先检查这个标识是否已经处理过。
2、 去重表:使用数据库或缓存系统(如 Redis)记录处理过的消息标识,避免重复处理。
3、 业务逻辑幂等性:确保业务操作本身是幂等的,例如扣款操作确保同一笔交易不会被重复扣款。
消息投递机制
RocketMQ 支持多种消息投递机制,可以根据业务需求选择合适的投递策略。
同步投递确保消息被可靠地发送到 Broker,并且发送方可以收到确认。通过这种方式,可以减少消息丢失的可能性。
RocketMQ 提供了消息重试机制,当消息投递失败时,会自动重试。为了避免重复投递,可以设置合理的重试次数和间隔时间。
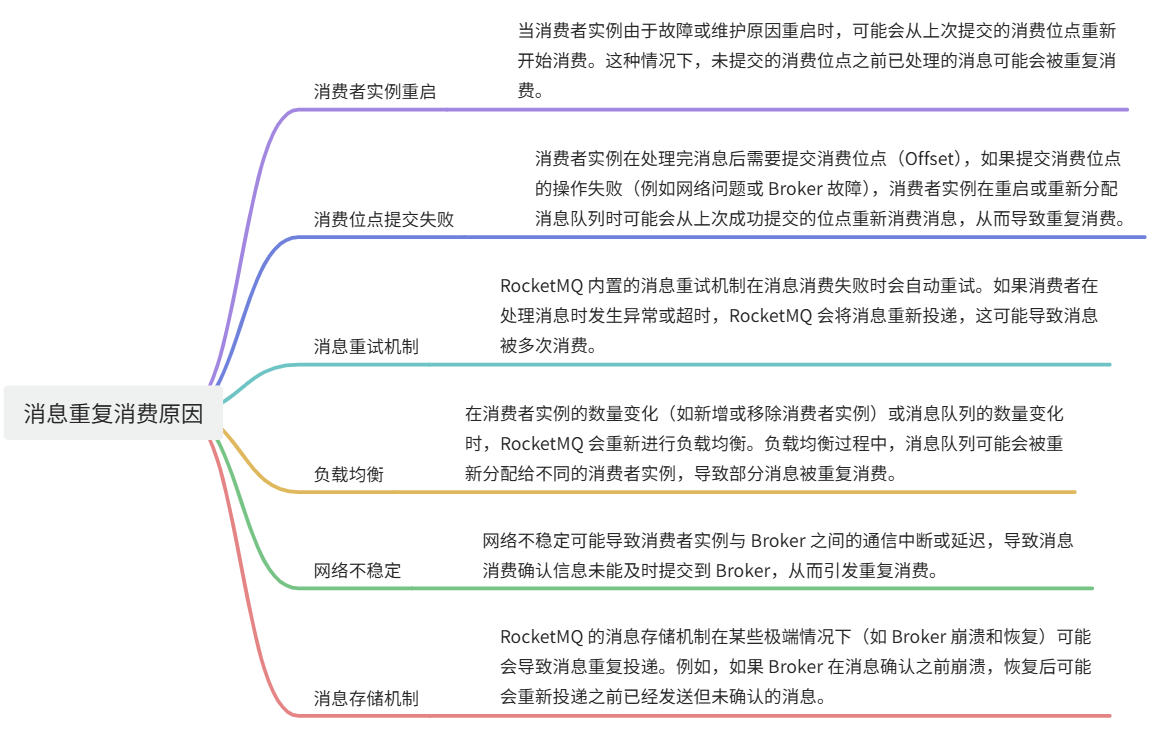
消费进度管理
消费进度管理是避免重复消费的关键。RocketMQ 通过消费位点(Offset)来管理消费进度。
消费者实例在消费消息后,需要定期提交消费位点到 Broker。这样即使消费者实例重启,也能从上次提交的位置继续消费。
消费位点可以存储在 Broker 或外部存储系统(如数据库、Zookeeper)中。确保消费位点的持久化存储,可以在消费者实例故障恢复后继续消费。
消息重复消费的原因
死信队列和延迟队列
死信队列(DLQ)
死信队列用于存储那些无法被正常处理的消息。这些消息被称为“死信消息”。消息进入死信队列的原因通常包括:
1、消息被消费多次但仍然处理失败。
2、消息在队列中存活时间超过了最大时间限制。
3、消息被拒绝(例如,消费者明确拒绝处理该消息)。
使用场景
错误处理:当消息处理失败多次后,将其放入死信队列,可以进行后续的人工干预或特殊处理。
监控和报警:通过监控死信队列,可以发现系统中的异常情况,及时进行报警和处理。
消息审计:对死信队列中的消息进行审计,分析系统中可能存在的问题。
实现方法
配置死信策略:在消息队列系统中配置死信策略,如最大重试次数、消息存活时间等。
专用死信队列:为每个队列配置一个专用的死信队列,存储无法处理的消息。
消费者处理:设置专门的消费者处理死信队列中的消息,进行日志记录、报警或其他处理。
延迟队列
延迟队列用于存储那些需要在指定时间后才能被消费的消息。消息在发送到延迟队列后,会在设定的延迟时间到达后才被投递到目标队列供消费者消费。
使用场景
定时任务:实现定时任务调度,如在指定时间发送通知、执行任务等。
重试机制:在消息处理失败后,将消息放入延迟队列,等待一段时间后再重新处理。
实现方法
消息定时属性:为消息设置定时属性,如延迟时间、到期时间等。
时间轮算法:使用时间轮算法管理延迟消息,定时检查并将到期的消息投递到目标队列。
解决消息队列的延时以及过期失效问题
解决消息队列的延时问题
1、增加消费者实例:增加消费者实例可以提高消息处理的并发度,从而减少消息的等待时间。
2、优化消费者处理逻辑:优化消费者的处理逻辑,减少每条消息的处理时间。例如,通过批量处理、异步处理、减少不必要的计算和 I/O 操作等方式来提高处理效率。
3、调整消息队列的分区:增加消息队列的分区数,使更多的消费者能够并行处理消息,从而提高处理速度。
4、 调整消息队列的配置:调整消息队列的配置参数,如增加内存缓冲区大小、优化网络配置等,以减少消息传输和处理的延时。
解决消息过期失效问题
1、 设置合理的消息过期时间:根据业务需求设置合理的消息过期时间,确保消息在有效期内被处理。
2、 使用死信队列(DLQ):将处理失败或过期的消息转移到死信队列,进行后续处理或人工干预。
解决消息积压的问题

Kafka、ActiveMQ、RabbitMQ、RocketMQ有什么优缺点
Apache Kafka
优点
- 高吞吐量:Kafka 设计用于处理高吞吐量的实时数据流,能够处理数百万条消息每秒。
- 持久化和可靠性:消息被持久化到磁盘,并且可以配置副本机制,保证消息的高可用性和可靠性。
- 水平扩展:Kafka 的分区机制允许其轻松扩展,增加更多的代理(broker)来处理更多的数据。
缺点
- 复杂的运维:Kafka 的部署和运维相对复杂,需要专门的运维人员来管理和监控 Kafka 集群。
- 高延迟:相对于内存中消息传递的系统,Kafka 的磁盘 I/O 操作会带来一定的延迟。
- 功能单一:Kafka 专注于高吞吐量和持久化,但在消息路由、优先级队列等高级特性上不如其他消息队列。
ActiveMQ
优点
- 丰富的特性:支持多种消息传递模型(点对点、发布-订阅)、消息持久化、事务、消息优先级、延迟消息等高级特性。
- 多协议支持:支持多种协议(如 AMQP、MQTT、STOMP、OpenWire 等),灵活性高。
- 简单易用:相对容易部署和使用,适合中小型企业和应用。
缺点
- 性能瓶颈:在高吞吐量和高并发场景下,ActiveMQ 的性能较 Kafka 和 RocketMQ 略显不足。
- 扩展性有限:虽然支持集群模式,但扩展性和水平扩展能力不如 Kafka 和 RocketMQ。
RabbitMQ
优点
- 灵活的路由机制:RabbitMQ 提供了复杂的消息路由机制(如交换器、绑定键、队列),支持多种消息传递和路由模式。
- 多协议支持:支持 AMQP、MQTT、STOMP 等多种协议,适用性广。
- 可靠性高:支持消息持久化、确认机制、事务等,保证消息的可靠传递。
缺点
- 性能限制:在极高吞吐量和低延迟场景下,RabbitMQ 的性能不如 Kafka 和 RocketMQ。
- 运维复杂度:在大规模集群中,RabbitMQ 的运维和管理相对复杂。
- 内存消耗:RabbitMQ 在处理大量消息时,内存消耗较高,需要合理配置和管理。
Apache RocketMQ
优点
- 高性能:RocketMQ 设计用于高吞吐量和低延迟的消息传递,性能接近 Kafka。
- 强大的消息路由:支持复杂的消息路由和过滤机制,灵活性高。
- 分布式事务:支持分布式事务,适合需要严格事务保证的场景。
- 扩展性强:支持水平扩展,能够轻松扩展集群规模。
- 可靠性高:支持消息持久化、副本机制,保证消息的高可用性和可靠性。
缺点
- 运维复杂度:RocketMQ 的部署和运维相对复杂,需要专业知识和经验。
RocketMQ消费模式有几种
集群消费
在集群消费模式下,多个消费者实例组成一个消费组(Consumer Group),每个消息只会被消费组中的一个消费者实例消费。这种模式适用于消息处理需要负载均衡的场景。每个消息只会被消费一次。适合需要处理大量消息的场景。
假设有一个消费组GroupA,包含两个消费者实例Consumer1和Consumer2。当生产者发送消息到主题TopicA时,消息会被分配给Consumer1或Consumer2,但不会同时被两个消费者实例消费。
2
3
4
5
6
7
8
9
10
TopicA --> msg1
TopicA --> msg2
msg1 --> Consumer1
msg2 --> Consumer2
subgraph GroupA
Consumer1
Consumer2
end广播消费
在广播消费模式下,多个消费者实例组成一个消费组,每个消息会被消费组中的所有消费者实例消费。这种模式适用于消息需要被多个消费者同时处理的场景。适合需要消息被多个消费者处理的场景,如日志处理、监控数据等。
假设有一个消费组GroupB,包含两个消费者实例Consumer3和Consumer4。当生产者发送消息到主题TopicB时,消息会被Consumer3和Consumer4同时消费。
2
3
4
5
6
7
8
9
10
11
TopicA --> msg1
TopicA --> msg1
msg1 --> msg2
msg1 --> msg2
msg2 --> Consumer3
msg2 --> Consumer4
subgraph GroupB
Consumer3
Consumer4
end
RocketMQ如何保证消息不丢失
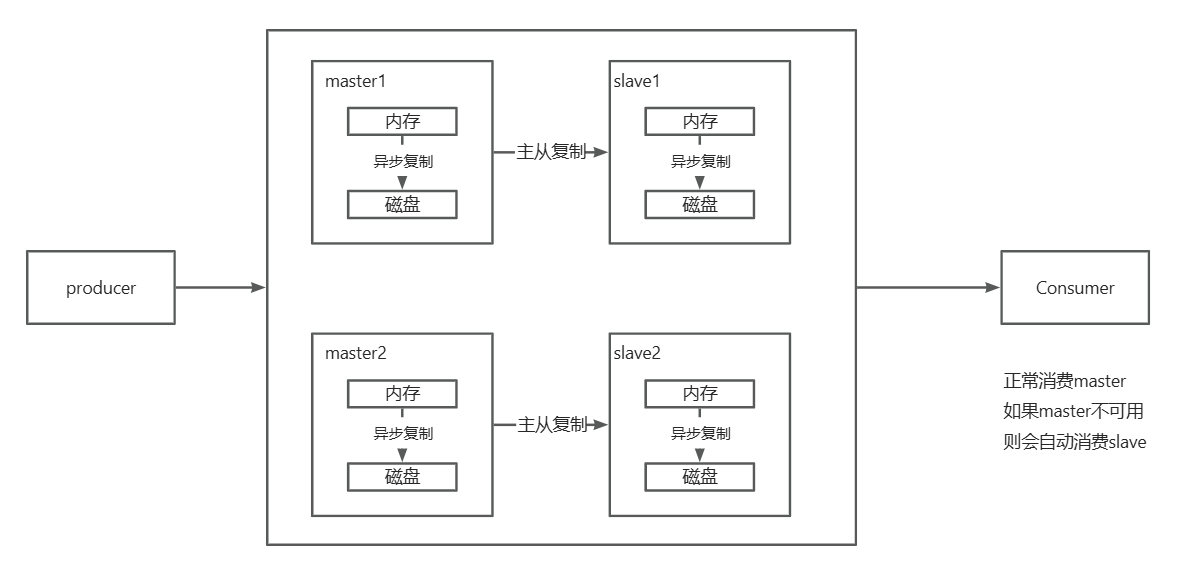
消息持久化
主要是靠的刷盘机制。RocketMQ 的磁盘消息保存在磁盘上,支持同步刷盘和异步刷盘两种方式,通过刷盘机制可以确保消息在Broker宕机时不会丢失。
同步刷盘(SYNC_FLUSH):消息写入后,立即同步刷盘,确保消息持久化到磁盘。同步刷盘虽然会增加延迟,但极大地提高了消息的可靠性。
异步刷盘(ASYNC_FLUSH):消息写入后,异步刷盘,性能较高,但可靠性略低于同步刷盘。
主从复制
RocketMQ 支持主从复制,通过将消息从主节点复制到从节点来提高消息的可靠性。主节点负责写入和读取,从节点负责复制数据。
同步复制(SYNC_MASTER):消息写入主节点后,立即同步复制到从节点,确保消息在主从节点都存在。同步复制提高了消息的可靠性,但会增加写入延迟。
异步复制(ASYNC_MASTER):消息写入主节点后,异步复制到从节点,性能较高,但可靠性略低于同步复制。
消息确认机制
RocketMQ 提供了消息确认机制,确保消息被消费者成功处理。
消费者确认:消费者处理完消息后,向 RocketMQ 发送确认(ack)。如果消费者未确认消息(如消费者崩溃),RocketMQ 会将消息重新投递给其他消费者。
2
3
4
5
6
7
8
>consumer.registerMessageListener(newMessageListenerConcurrently() {
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
// 处理消息逻辑
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; // 处理成功
}
>});重试机制
RocketMQ 提供了消息重试机制,确保消息在处理失败时不会丢失。
生产者重试:生产者在消息发送失败时,可以进行重试,确保消息成功发送。
消费者重试:消费者在处理消息失败时,RocketMQ 会自动进行重试,直到消息被成功处理或达到最大重试次数。
RocketMQ如何做负载均衡
负载均衡策略
RocketMQ 提供了多种负载均衡策略,常用的有以下几种:
平均分配(AllocateMessageQueueAveragely)
这是默认的负载均衡策略,将消息队列均匀分配给消费者组中的每个消费者实例。
示例: 假设有一个主题TopicA,包含 4 个消息队列Q1、Q2、Q3、Q4,消费者组GroupA中有 2 个消费者实例Consumer1和Consumer2。使用平均分配策略时,Consumer1可能会分配到Q1和Q2,而Consumer2分配到Q3和Q4。
按环形分配(AllocateMessageQueueByCircle)
这种策略将消息队列按顺序循环分配给消费者实例。
示例: 假设有 3 个消息队列Q1、Q2、Q3,消费者组中有 2 个消费者实例Consumer1和Consumer2。使用按环形分配策略时,Consumer1可能会分配到Q1和Q3,而Consumer2分配到Q2。
自定义分配策略
RocketMQ 允许用户实现自定义的负载均衡策略。用户可以通过实现AllocateMessageQueueStrategy接口,定义自己的消息队列分配逻辑。
负载均衡过程
负载均衡过程通常在以下几种情况下触发:
消费者实例启动:当新的消费者实例加入消费者组时,RocketMQ 会重新分配消息队列。
消费者实例停止:当消费者实例停止或崩溃时,RocketMQ 会重新分配该实例负责的消息队列给其他存活的消费者实例。
定时任务:RocketMQ 内部有定时任务定期检查和调整消息队列的分配情况,确保负载均衡的持续有效。
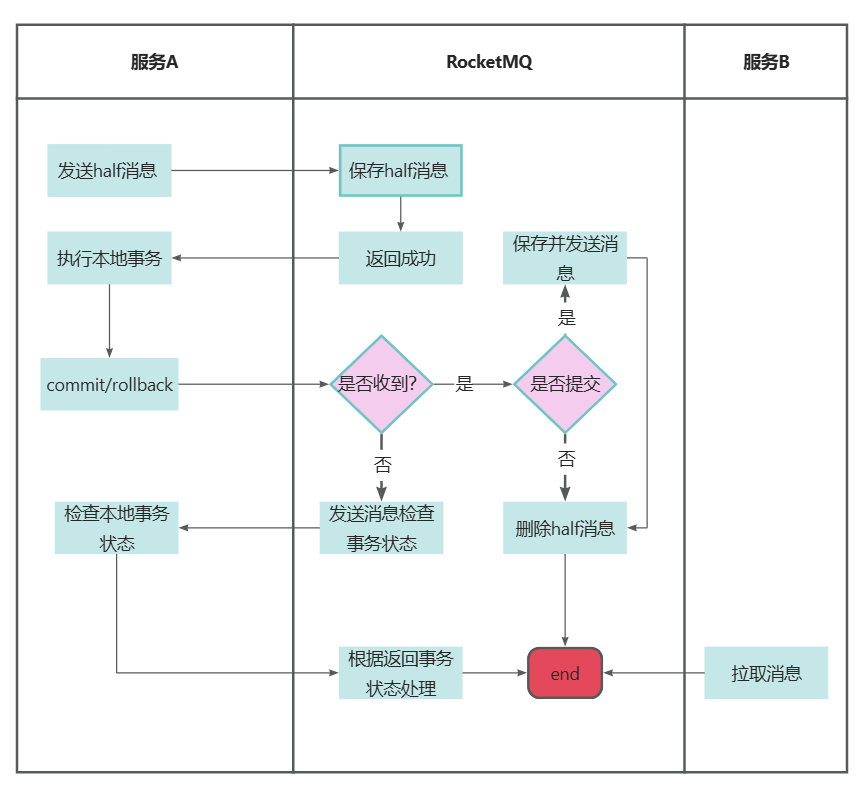
RocketMQ在分布式事务下的底层原理
RocketMQ 提供了分布式事务支持,主要通过两阶段提交(Two-Phase Commit)协议来实现
事务消息发送流程
分布式事务消息发送过程分为三个阶段:准备阶段、提交/回滚阶段和事务状态检查阶段。
准备阶段(Prepare Phase)
在这个阶段,消息生产者发送一条预备消息(Prepare Message)到 RocketMQ Broker。预备消息会被持久化到 Broker,但不会被消费者消费。
2
3
4
5
6
7
8
9
10
11
>producer.setNamesrvAddr("localhost:9876");
>producer.start();
>// 定义事务监听器
>TransactionListener transactionListener = new TransactionListenerImpl();
>producer.setTransactionListener(transactionListener);
>Message msg = new Message("TopicTest", "TagA", ("Hello RocketMQ").getBytes());
>TransactionSendResult result = producer.sendMessageInTransaction(msg, null);
>System.out.printf("%s%n", result);提交/回滚阶段(Commit/Rollback Phase)
在本地事务执行完毕后,生产者会根据本地事务的执行结果来提交(Commit)或回滚(Rollback)之前的预备消息。提交消息会使得消息对消费者可见,而回滚消息则会删除预备消息。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// 执行本地事务逻辑
boolean success = executeLocalBusinessLogic();
if (success) {
return LocalTransactionState.COMMIT_MESSAGE;
} else {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 检查本地事务状态
boolean success = checkLocalTransactionStatus();
if (success) {
return LocalTransactionState.COMMIT_MESSAGE;
} else {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
>}事务状态检查阶段(Transaction Status Check Phase)
如果在预备消息发送之后,由于网络或其他原因导致生产者未能及时提交或回滚事务,Broker 会定期向生产者询问事务的状态。生产者需要实现checkLocalTransaction方法来返回事务的实际状态。
事务消息的存储和状态管理
RocketMQ 在 Broker 端会持久化预备消息,并在消息的元数据中记录其状态(准备中、已提交、已回滚)。当生产者提交或回滚事务时,Broker 会更新消息的状态。
消费者处理事务消息
消费者在消费消息时,不会区分事务消息和普通消息。事务消息在被提交后,消费者才能消费到这些消息。
事务消息的可靠性保证
消息持久化:RocketMQ 对预备消息进行持久化存储,确保消息不会丢失。
事务状态检查:通过事务状态检查机制,确保最终事务的一致性。
重试机制:在事务消息的各个阶段都有重试机制,确保消息的可靠传递和处理。
事务消息的示例代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
public static void main(String[] args) throws MQClientException {
TransactionMQProducer producer = new TransactionMQProducer("ProducerGroupName");
producer.setNamesrvAddr("localhost:9876");
producer.setTransactionListener(new TransactionListenerImpl());
producer.start();
try {
Message msg = new Message("TopicTest", "TagA", ("Hello RocketMQ").getBytes());
TransactionSendResult result = producer.sendMessageInTransaction(msg, null);
System.out.printf("%s%n", result);
} catch (MQClientException e) {
e.printStackTrace();
}
// 保持生产者运行,模拟执行本地事务
Runtime.getRuntime().addShutdownHook(new Thread(producer::shutdown));
}
>}
>class TransactionListenerImpl implements TransactionListener {
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// 执行本地事务逻辑
boolean success = executeLocalBusinessLogic();
if (success) {
return LocalTransactionState.COMMIT_MESSAGE;
} else {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 检查本地事务状态
boolean success = checkLocalTransactionStatus();
if (success) {
return LocalTransactionState.COMMIT_MESSAGE;
} else {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
private boolean executeLocalBusinessLogic() {
// 模拟本地事务执行
return true; // 返回事务执行结果
}
private boolean checkLocalTransactionStatus() {
// 模拟检查本地事务状态
return true; // 返回事务状态
}
>}
为什么不应该对所有的message 都使用持久化机制
性能开销
持久化操作通常涉及磁盘 I/O 操作,而磁盘 I/O 的速度远低于内存操作。频繁的持久化会导致系统性能下降,包括消息发送和接收的延迟增加。每次消息持久化都需要写入磁盘,增加了消息发送的延迟。高频率的磁盘 I/O 会限制系统的整体吞吐量。
资源消耗
持久化消息需要存储在磁盘上,这会占用大量的存储空间。对于高频率、大量的消息传输场景,存储成本会显著增加。大量持久化消息会迅速消耗磁盘空间。
复杂性和维护成本
持久化机制增加了系统的复杂性,需要额外的维护和管理。例如,需要定期清理过期的持久化消息,确保磁盘空间的可用性。
应用场景需求
并非所有应用场景都需要消息持久化。对于一些实时性要求高但对消息可靠性要求不高的场景,持久化反而会带来不必要的开销。比如实时性要求高的场景:如实时数据流处理、临时通知等,不需要持久化。又比如可靠性要求低的场景:如缓存更新通知、统计数据等,丢失少量消息对系统影响不大。





